非随机对照试验样本量,非随机对照试验样本量估算方法与原则
想象你是一位临床研究新手,面对着一堆数据和一堆复杂的统计方法,突然被问到这样一个问题:“非随机对照试验样本量到底该怎么算?”这个问题像一块巨石压在心头,让你喘不过气。别担心,今天我们就来一起揭开这个神秘的面纱,让你轻松掌握非随机对照试验样本量的计算方法。
非随机对照试验样本量的重要性
在临床研究中,样本量的大小直接影响着研究结果的可靠性和有效性。如果样本量过小,可能会导致结果不准确,甚至无法得出有意义的结论。相反,如果样本量过大,不仅会增加研究的成本和时间,还可能因为过多的无效干预而给受试者带来不必要的风险。因此,如何科学合理地计算非随机对照试验的样本量,是每一位研究者都必须面对的挑战。
非随机对照试验样本量的计算方法

非随机对照试验样本量的计算方法与随机对照试验有所不同,因为非随机分组可能导致组间基线特征存在差异,从而影响结果的可靠性。因此,在计算样本量时,需要考虑以下几个关键因素:
1. 效应量
效应量是指处理组与对照组之间的差异程度。在非随机对照试验中,效应量通常通过文献回顾、预试验或专家意见来估计。例如,如果你正在研究一种新的降压药,可以通过查阅文献或进行小规模预试验来估计新药与安慰剂在降低血压方面的差异。
2. 统计效能
统计效能是指试验能够正确检测出真实差异的能力。通常,统计效能取值为0.8或0.9,表示试验有80%或90%的概率检测出真实差异。统计效能越高,所需的样本量就越大。
3. 显著性水平
显著性水平是指拒绝原假设的概率,通常取值为0.05或0.025。显著性水平越低,所需的样本量就越大。
4. 组间差异
非随机分组可能导致组间基线特征存在差异,因此在计算样本量时需要考虑组间差异。例如,如果两组在年龄、性别或疾病严重程度等方面存在显著差异,可能需要更大的样本量来确保结果的可靠性。
5. 失访率
失访率是指受试者在试验过程中退出或失联的比例。失访率越高,所需的样本量就越大。
实际案例分析
让我们通过一个实际案例来理解非随机对照试验样本量的计算过程。假设你正在研究一种新的抗抑郁药物,已知安慰剂组的有效率为50%,你希望新药的有效率至少比安慰剂高10%,显著性水平取0.05,统计效能取0.8,失访率取10%。
步骤1:确定效应量
效应量 = 新药有效率 - 安慰剂有效率 = 10%
步骤2:确定统计效能和显著性水平
统计效能 = 0.8,显著性水平 = 0.05
步骤3:考虑失访率
失访率 = 10%
步骤4:使用样本量计算公式
对于二分类变量,样本量计算公式为:
\\[ n = \\frac{(Z_{1-\\alpha/2} + Z_{1-\\beta})^2 \\cdot (P_1(1-P_1) + P_0(1-P_0))}{(P_1 - P_0)^2} \\]
其中,\\( Z_{1-\\alpha/2} \\) 是显著性水平对应的Z值,\\( Z_{1-\\beta} \\) 是统计效能对应的Z值,\\( P_1 \\) 是新药组的有效率,\\( P_0 \\) 是安慰剂组的有效率。
代入数值:
\\[ n = \\frac{(1.96 + 0.84)^2 \\cdot (0.6 \\cdot 0.4 + 0.5 \\cdot 0.5)}{(0.6 - 0.5)^2} \\]
\\[ n = \\frac{(2.8)^2 \\cdot (0.24 + 0.25)}{0.01} \\]
\\[ n = \\frac{7.84 \\cdot 0.49}{0.01} \\]
\\[ n = 384.96 \\]
步骤5:考虑失访率
实际样本量 = 计算样本量 / (1 - 失访率) = 384.96 / (1 - 0.1) = 427.17
因此,每组需要约428名受试者,总共需要约856名受试者。
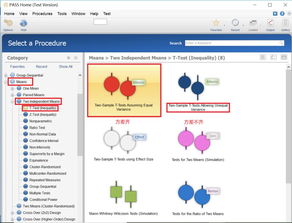
使用PASS软件计算样本量
除了手动计算,还可以使用PASS软件来计算非随机对照试验的样本量。PASS是一款专业的样本量计算软件,提供了多种统计方法,可以满足不同研究设计的样本量